
Real Time Analytics
This article includes the following sections:
- Introduction
- Real Time Fraud Detection
- Building the Model in Alpine
- Scoring Transactions in Real Time
- Extending Your PMML
- Conclusion
Introduction
Many companies have realized the value of applying machine learning techniques to the data they’ve already collected in a batch oriented way, but a lot of them are still struggling to apply the same concepts to data as it’s being generated in real time. Scoring data in real time is useful for any use case where making time sensitive decisions is important. Traditional examples include fraud detection and clickstream analysis. Real time analytics is becoming even more important as the Internet of Things continue to evolve. Interconnected machines need a way to programmatically apply advanced analytics to the vast amounts of data they are generating.
This article describes a technique for using Alpine and Openscoring to build a model, deploy it, and automatically use it to score new data as it is generated.
Case Study: Real Time Fraud Detection
As an example, consider the use case of determining whether or not an online transaction is fraudulent. Most online retailers have an eCommerce webstore that allows customers to add items to a virtual shopping basket, enter their payment information, and instantly check out. Most transactions that take place in this way are completely legitimate, but fraudulent transactions do happen and they can end up costing retailers a lot of money.
Sophisticated machine learning models can be developed to detect fraudulent transactions in a variety of ways. However, integrating fraud detection models into the online transaction flow is often more difficult then creating the model itself. Each order needs to be scored for its likelihood to be fraudulent and then automatically rejected if it exceeds a certain probability threshold. At the same time it is important to keep the false positive rate as low as possible to avoid rejecting legitimate transactions.
Building the Model in Alpine
First, consider the data elements that typically constitute an online order. We know some basic information about the user, the items they wish to order, their billing and shipping addresses, and their payment information. We need a historic record of as many transactions as possible in order to train our model. We also need to add a new column to our data called fraudulent that indicates which past transactions were actually fraudulent. Because we’re using Alpine, this historic data could be stored in either Hadoop or a relational database.
::mysql
=> \d orders
Table "public.orders"
Column | Type | Modifiers
-------------------+---------+-----------\
fraudulent | integer |
amount | numeric |
user_email | text |
user_id | text |
billing_address1 | text |
billing_city | text |
billing_state | text |
billing_zipcode | text |
billing_country | text |
shipping_address1 | text |
shipping_city | text |
shipping_state | text |
shipping_zipcode | text |
shipping_country | text |
cc_type | text |
cc_number | bigint |
cc_cvv | integer |
The next step is to determine which variables we want to use in our model. This process is known as exploration. We might start by simply making an educated guess about which variables in our data are likely to predict fraud, but as we iterate and refine our model we will probably end up transforming our data to create new calculated variables. The model used in this example is rather simple and uses just three calculated variables. The variables used in our example model are:
- billing_ne_shipping - 1 if the billing address is not the same as the shipping address, 0 if they are the same
- international_shipping - 1 if the shipping address is outside the US, 0 if it is domestic
- large_order - 1 if the total amount of the order exceeds $1000, 0 if it is less than $1000
In practice we could achieve better results by taking a more sophisticated approach to picking and calculating variables, but these give us a good starting point for this example.
Next we use Alpine’s Visual Workflow Interface to train and validate our Logistic Regression model:
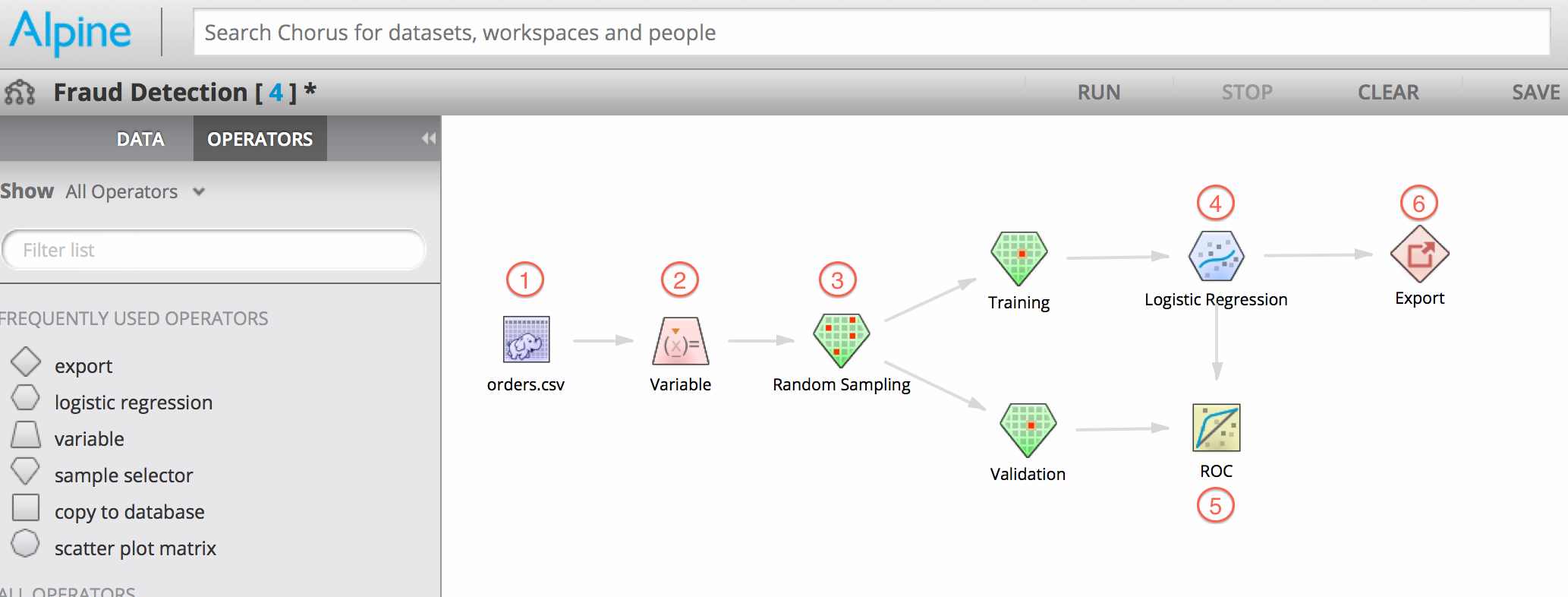
The steps in the above workflow are described as follows:
- Add our data to the workflow, in this example our order history is a CSV file in a Cloudera system
- Use the Variable operator to create the three calculated variables described above using Pig
- Split the data into a Training set and Validation set using the Random Sampling operator
- Build a Logistic regression model using our training data set
- Validate the accuracy of our model by using it to score our validation data set and plot a corresponding ROC curve
- Export our finished model as PMML
Building the above model is a highly iterative process which should include data scientists as well as business stakeholders. We know that we are ready to operationalize the model, or deploy it to production, when everyone involved validates the model and agrees it is accurate enough to solve the given business problem.
One way to assess the accuracy of a model is by constructing a ROC curve. The ROC curve for the model in our example is shown below:
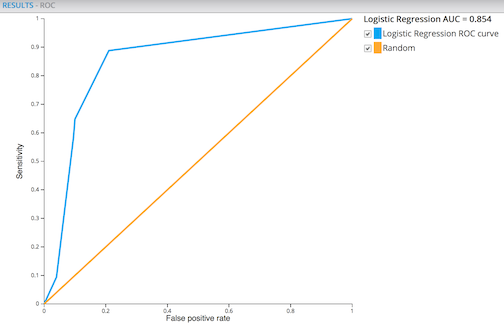
After we’ve run the model in Alpine, either manually through the interface or by programmatically calling the Alpine API, we will see both the Fraud Detection Workflow as well as the resulting fraud_detection.pmml show up in our project Work Files.
Scoring Transactions in Real Time
PMML stands for Predictive Model Markup Language and is an open standard for describing machine learning models. The Data Mining Group is the consortium that develops and maintains the PMML standard. A variety of different products are certified to be either producers or consumers of PMML.
Once we’ve trained our model in Alpine and exported it as PMML, we can use it with any PMML consumer to begin scoring our data. There are open source PMML consumers such as JPMML, as well as commercial offerings such as Zementis. Which one is right for you will depend on the level of support you require and the difficulty of integrating them into your transaction flow. Also keep in mind that it is even possible to write your own consumer for specialized circumstances since PMML is an open standard.
For this example we will take advantage of the open source Openscoring REST web service. We simply download the software package from Github and install it as described in the documentation. Keep in mind that Java 1.7 is required.The REST API for working with PMML will be available on port 8080 once we start the Openscoring server:
::sh
java -jar server/target/server-executable-1.1-SNAPSHOT.jar
Once the REST service is running we can issue a PUT request to load our PMML model. Remember that we downloaded the .pmml file from Alpine to our local system before running this command. Note that Openscoring supports using multiple models at the same time and the URL we provide, “/openscoring/model/FraudDetection” indicates that we will use FraudDetection to refer to this model in the future.
::sh
curl -X PUT --data-binary @fraud_detection.pmml -H "Content-type: text/xml" http://$OSHOST:8080/openscoring/model/FraudDetection
Now that our model has been loaded we can begin integrating with our eCommerce webstore. As each order is submitted, or webstore needs to create a JSON object containing the variables expected by the model and then submit that model to the Openscoring server. In our example, the JSON object for a given transaction might look like this:
::json
{
"id" : "example-001",
"arguments" : {
"large_order" : 1,
"billing_ne_shipping" : 0,
"international_shipping" : 1
}
}
We can score this order by including the JSON object in a POST request to our Openscoring server:
::sh
curl -X POST --data-binary @FraudRequest.json -H "Content-type: application/json" http://$OSHOST:8080/openscoring/model/FraudDetection
The prediction of whether or not this transaction is fraudulent will be returned by the web service immediately. In this sample transaction we indicated it was an order greater than $1000 and it would be shipped internationally. Our model returns a ‘1’ which means this transaction is likely fraudulent:
::json
{
"result": {
"fraudulent": "1"
},
"id": "example-001"
}
At this point our application knows the transaction is likely fraudulent and can programmatically decide how to handle that. It might cancel the transaction all together, or perhaps it will request additional information from the buyer. Over time the model can be refined and improved as more data is gathered, but our application will simply continue to use the same REST API.
Extending Your PMML
Since PMML is an open standard, it is also possible to extend the PMML documents generated by your PMML producer of choice. You can tweak the model directly, or you can add additional directives or tasks to your PMML document. One thing you might want to do is add an automatic transformation to your PMML that derives a new variable from your input. In the above example this would allow your application to simply pass the actual amount of the transaction and have the large_order column calculated automatically.
Notice that the above output showed us only a 0 or a 1 to indicate whether or not the transaction is fraudulent. While this is useful, it would might be more helpful to know the exact confidence of the model. To do this we can can add an Output block to our PMML document:
::xml
<Output>
<OutputField name="P_fraudulent" optype="categorical" dataType="string" feature="predictedValue"/>
<OutputField name="C_fraudulent" optype="continuous" dataType="double" targetField="fraudulent" feature="probability" value="1"/>
</Output>
Our model will now return the C_fraudulent confidence value in the JSON result that shows us the probability that our result is correct. Notice that the output from the REST call now shows us a ~71% confidence that the transaction is fraudulent. This will allow us to set a threshold for denying a transaction inside our application.
::json
{
"result": {
"C_fraudulent": 0.709966038470281,
"P_fraudulent": "1",
"fraudulent": "1"
},
"id": "example-001"
}
Conclusion
Alpine, R, SAS, and many others analytics tools are capable of producing PMML documents that can be leveraged by real time applications. Since PMML is an open standard, those documents can be modified in a variety of ways to meet application specific needs. Scoring can be done using open source, proprietary, or even home grown tools. This article discusses detecting fraud in online transactions, but the same principles can be used to apply machine learning models to any stream of real time data.
comments powered by Disqus