
Enabling Big Science
Collecting data is only half of the Big Science battle. Much like a carpenter needs a hammer and nails, your data scientists need the correct tools to effectively distill value from your data. All too often companies make the mistake of only considering how to store their data, when in reality storage is only one component of the big data tool belt. Ingestion, provisioning, cataloging, and querying must also be considered.
When designing the architecture of your big data ecosystem always be sure that enabling your data scientists is your top priority. The following diagram shows the components and flow of an environment ideal for effective data science. There are many technologies that can be used to provide each part of the architecture, but making sure you have each component is much more important than the specific technologies you choose to implement.
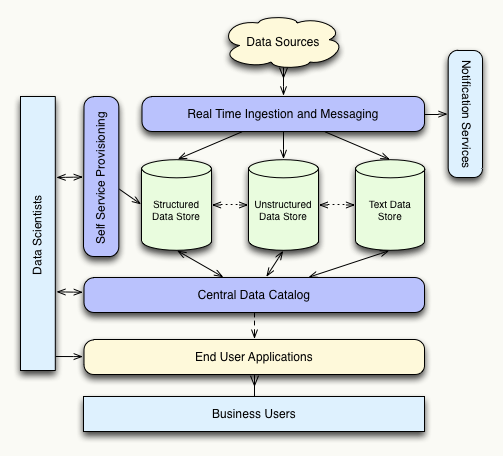
Self service provisioning system
Big Science happens in real time, so effective data scientists can’t wait for DBAs or system administrators to move data or create new data stores for them. A self service provisioning system should allow for autonomously creating sandboxes in any of the available data storage systems, whether that be a MapReduce environment, an MPP warehouse, or a text analytics engine. Data scientists should also be able to use the provisioning system to easily move data between environments. Just because a data set is best queried with MapReduce today doesn’t mean a new problem wont necessitate that it be queried with SQL tomorrow.
Central data catalog
A side effect of enabling self provisioning is that data can essentially become lost. A data scientist trying to solve a specific problem might create a new database table and load it with data from HDFS only to find that a MapReduce solution is more efficient. If users aren’t diligent about cleaning up after themselves they could potentially end up with unused data scattered throughout the environment. It also might be the case that two data scientists working on different problems create data sets that are essentially the same without even knowing it. Data repetition and unused data can both become serious problems that are easily solved with a central data catalog.
A central data catalog should provide a single source of metadata for all the different data storage systems in the environment. It should allow data scientists to tag and track the data sets they are creating so it is easy to determine when unused data sets can be cleaned up. The central catalog should also be a social system that allows users to share information with each other. Data scientists should be able to share the data sets they create as well as information about how they used the data to solve their given problems.
Real time ingest
When possible, data should be brought into the system using a single, real time ingest point. Most use cases may not require real time data loading, but using a single system simplifies the process of bringing on new data source and making it real time gives you maximum future flexibility.
The most efficient real time ingestion systems are often in-memory solutions, so data should be passed from the real time system to a final data storage system as it is loaded. A DBA might have to determine which storage location is right for each new data store, but data scientists should have the ability to later choose a different data store through the self service provisioning system.
Notification Services
Although data will be coming into your system in real time, it often wont be queried by data scientists in real time. The primary benefit of having real time data is the automated alerting and push notification services that can utilize it. Different events, such as data outside of expected norms, can trigger alerts that notify individuals responsible for monitoring or correcting specific problems.
Notification services are especially useful in applications that deal with fraud detection, financial services, and system monitoring. When companies are quickly notified of critical events they can take immediate action to improve customer satisfaction or in some cases save significant amounts of money.
Types of data storage systems
The types of data storage systems you choose to implement in your environment will vary greatly depending on your data sources and business use cases. The three main categories of data storage systems are: structured, unstructured, and text. Most companies will deal with all three types of data at one time or another, so plan accordingly when designing your architecture. Also keep in mind that some hybrid systems will allow you to store multiple types of data in the same environment, so three different data stores may not be necessary.
Structured storage – Data warehouse
Structured data is the most common type of data companies deal with today. It can be broken into rows and columns with each record in each table having the same number of fields with the same data types. Structured data stores are most commonly queried through SQL. Most companies use them as a central place for reporting and long term data storage. Since many reports are business critical, proper resource management is key to allowing data scientists to work on the same system where production reporting is taking place.
An example of structured data:
1997,"Ford","E350"
2001,"GMC","Sierra"
Unstructured storage – NoSQL, Hadoop, etc.
An unstructured data store is capable of storing records that do not conform to the same format. Records of the same type can have a different number of attributes and they can even be of different types. SQL does not usually work well with this type of data, so it is most commonly queried using MapReduce or a similar programmatic query language. Data scientists typically use this type of data store for exploration of new ideas or answering one off questions. Unstructured storage can be used as a source for end-user facing reporting systems, but it is far more common for those applications to be connected to a structured data source.
An example of unstructured data:
"localhost",2013-02-01,"GET",200
Unexpected internal error
10.10.0.1,2013-02-02,"POST",405,"invalid request"
Text analytics
Text data is becoming more and more prevalent in corporate environments. Text sources include email, social media such as Facebook or Twitter, and documents such as Word or PDF. Text data is typically semi-structured, so is often combined with either the structured or unstructured data stores, but for most text analytics applications it is useful to have a system specialized for that type of work. Text data is used for eDiscovery, sentiment analysis, government intelligence, email classification, and many other emerging sources.
An example of text data:
"Subject","[email protected]",2013-02-01,"Very long body of an email message"
Conclusion
When planning the architecture of your Big Data Ecosystem be sure to provide your data scientists with all the tools they need to be successful. Spend time considering all the potential data sources your organization might have; don’t rush to technology decisions based on the current state of your architecture. It is tempting to provide your analysts with a single data storage and querying system, but not all data problems can be solved in a single environment. Give your data scientists the freedom and flexibility to choose the right platform for the job and the tools they need to collaborate and keep all the platforms organized.