
Putting Big Data to Work
Companies around the world have by and large bought into the benefits of Big Data. They are collecting and keeping more data than ever before, but most of the time all that Big Data is not earning its keep.
Business users are looking for concise reports or summaries of the data. Solution developers don’t have the expertise or domain knowledge to coherently present the raw data being collected on their own. Analysts aren’t able to help because the data they need is stored in disparate systems without a central catalog. The right data exists, but because it can’t be synthesized and presented to decision makers in a timely fashion it never makes an impact on real business problems.
Organizations need to put their big data to work by building more efficient Data Workflows.
Data Stakeholders
Before we can develop a big data workflow we must first understand the different groups that play a critical role in the data ecosystem. People usually think only in terms of producers and consumers, but in reality their are four important groups that must be considered.
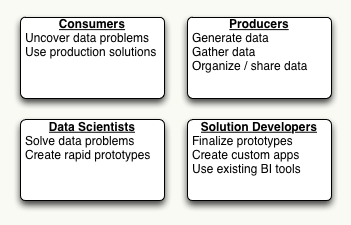
1. Consumers
Consumers or business users have problems that need to be solved. They have a keen understanding of the issues facing their business unit, but usually don’t have the time or technical expertise to analyze raw data. They can be represented by any area of the business, from marketing to sales to research and development.
These users should be leveraged in two key ways:
- Uncovering new problems that can be solved with big data
- Using data applications to make an impact on the business
2. Producers
The producers bring data into the organization. They could be a business unit that is actively generating data, such as website traffic logs, or gathering data from third parties, such as Twitter or Facebook. In some cases Consumers can also be Producers. For example, a marketing group interested in sentiment analysis may bring a Twitter data stream into the organization, but they usually wont have the ability to perform the sentiment analysis themselves.
A key mistake that producers often make is to inadvertently silo the data they bring into the organization so it can’t be leveraged by other groups. To prevent this problem, producers should be enabled in the following ways:
- They should be able to rapidly provision their own data repositories through a central system
- There should be a variety of options for storing their data – such as structured and unstructured repositories
- They should be able to organize and share their data sources through a central catalog
3. Data Scientists
Data Scientists are capable of taking raw data and using it to solve given business problems. The most common mistake that organizations make with their Data Science teams is to give them access to raw data and ask them to do something interesting with it. This almost always leads to long projects with results that can’t actually be used by the business. They should always be approached with problems that need to be solved.
The following are the keys to effectively utilizing a Data Science team:
- Always bring specific business problems to the Data Science team
- Make it easy to find, share, and combine data through a central repository system
- Allow and expect the Data Scientists to iterate multiple times before finding an optimum solution
- Don’t expect results to be usable directly, they should almost always be given to a solution team to ‘productionalize’ before use
4. Solution Developers
Armed with knowledge of the business problem and the output from the Data Science team, Solution Developers build applications or automated processes that can be used directly by the Consumers. These could be as simple as automated reports built with an out of the box BI tool, or as complex as a custom built, customer facing application. The right choice will depend on the intended audience of the solution.
Data Workflows
The following flowchart outlines a generic workflow that leads from a real business problem to a production application that business users can derive value from. Note that all the stakeholders defined above are completely orthogonal.
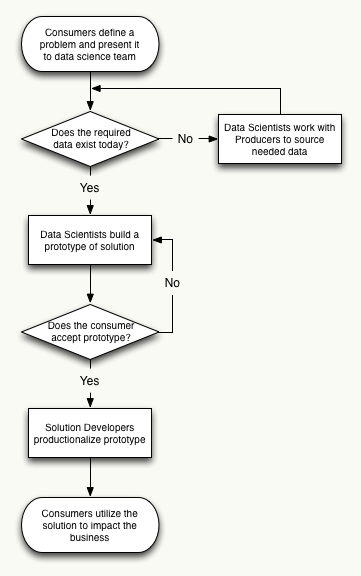
Workflow Example Scenario
The following scenario illustrates how the above workflow could be put into practice:
- A marketing department wants to better understand what causes customer churn so they can proactively prevent it
- They approach the Data Science team and ask them to identify the most commonly occurring event that happens to users before they unsubscribe
- The Data Science team quickly sources call data from the customer support department, web traffic data from IT operations, and customer account data from the billing department
- The data science team does an initial investigation and generates several hypotheses
- They rapidly build several likely customer churn models and present them to marketing who provide feedback
- Data Science determines that web site outages have the most impact on customer churn and turn their final model over to the Solution Development team
- The Solution Development team builds a daily report for marketing that shows customers who have been recently affected by website outages as well as an alerting system that helps IT operations quickly respond to web site outages
- The marketing department uses their daily report to reach out to affected customers and succeeds in reducing churn
Conclusion
Organizations can increase the value of the Big Data they are already storing by clearly defining the roles and responsibilities of the key data stakeholders. Workflows can be established that allow each group to be as orthogonal as possible in order to maximize efficiency and business value.