
Custom Alpine Operators
This article includes the following sections:
Alpine Plugin Introduction
Alpine’s workflow builder is a visual programming environment. This means that instead of coding models by hand in languages like R or Python, data scientists are able to use Alpine to create analytic workflows by dragging operators onto a canvas and linking them together in series. As illustrated in the below picture, an analyst might first drag out the data sets they want to work with, join them together, transform them in various ways, and then link the transformed data to a model of their choice.
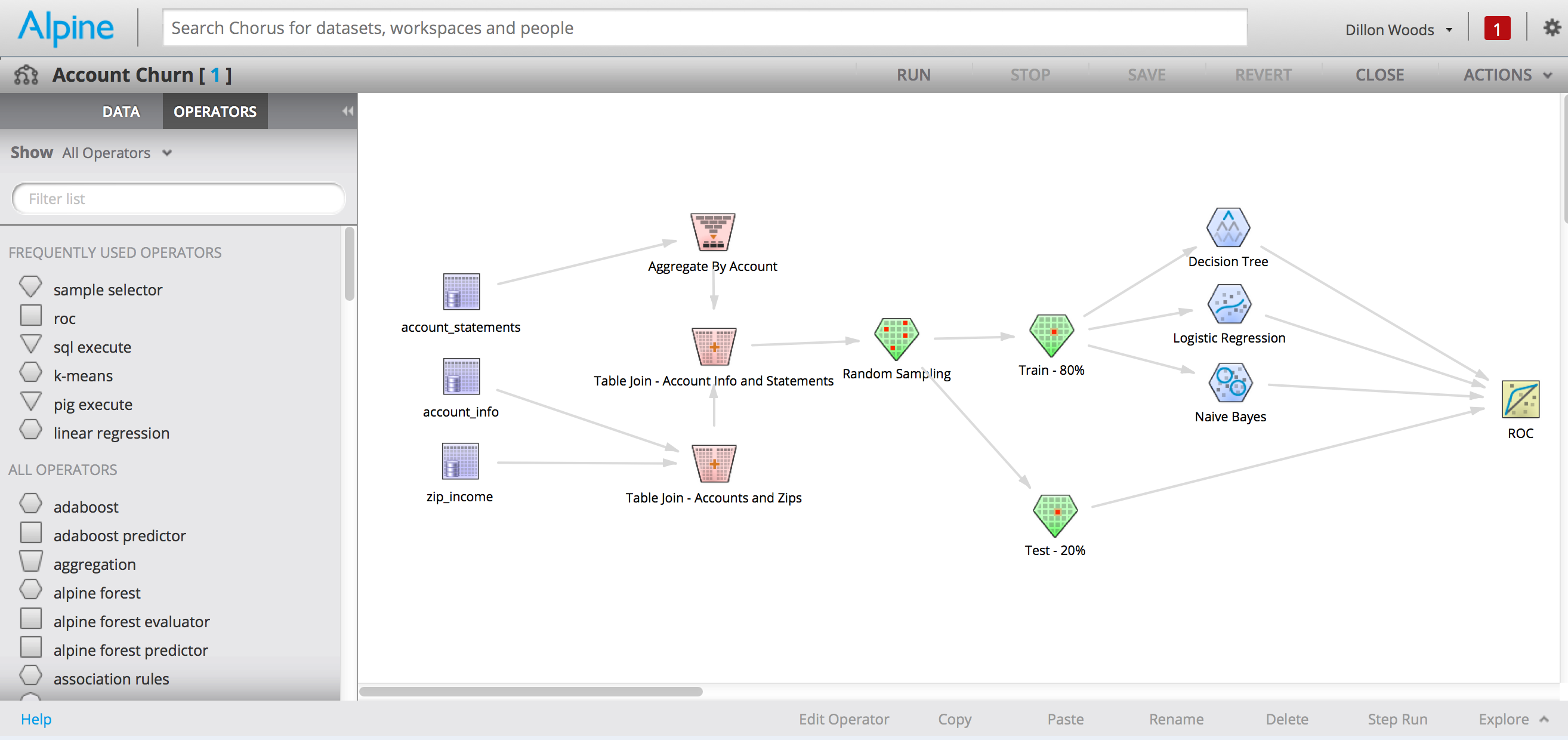
Alpine ships with a wide variety of operators for all phases of the analytics workflow: data loading, exploration, transformation, sampling, and modeling. All told there are over eighty built-in operators available out of the box. Even though this seems like a large number, users will always encounter edge cases where a certain operator doesn’t quite work they way they want. Or maybe they have a novel approach to improve the performance or accuracy of an existing statistical model. Alpine provides a robust plugin framework so users can create their own operators to address these types of scenarios.
MADLib Case Study
One of the best examples of the Alpine Plugin Framework in action is the set of MADLib extensions for Alpine. MADLib is an open-source library for scalable in-database analytics. This popular library supports Greenplum, PostgreSQL, and HAWQ. MADLib algorithms are implemented as user defined functions in the database, so users usually interact with them through SQL. This limits their appeal since it isn’t easy to incorporate SQL functions calls into a typical data science workflow.
To solve this problem developers were able to easily create a set of MADLib operators for Alpine using the Plugin Development Kit. This allows users to use MADLib operators inside the Alpine visual programming environment with any data source that supports MADLib. It also gives data scientists a choice when building model workflows: they can use the built-in Alpine implementation of a model or choose to use the MADLib implementation. They can even use both within the same flow to find the one with the best performance or result characteristics.
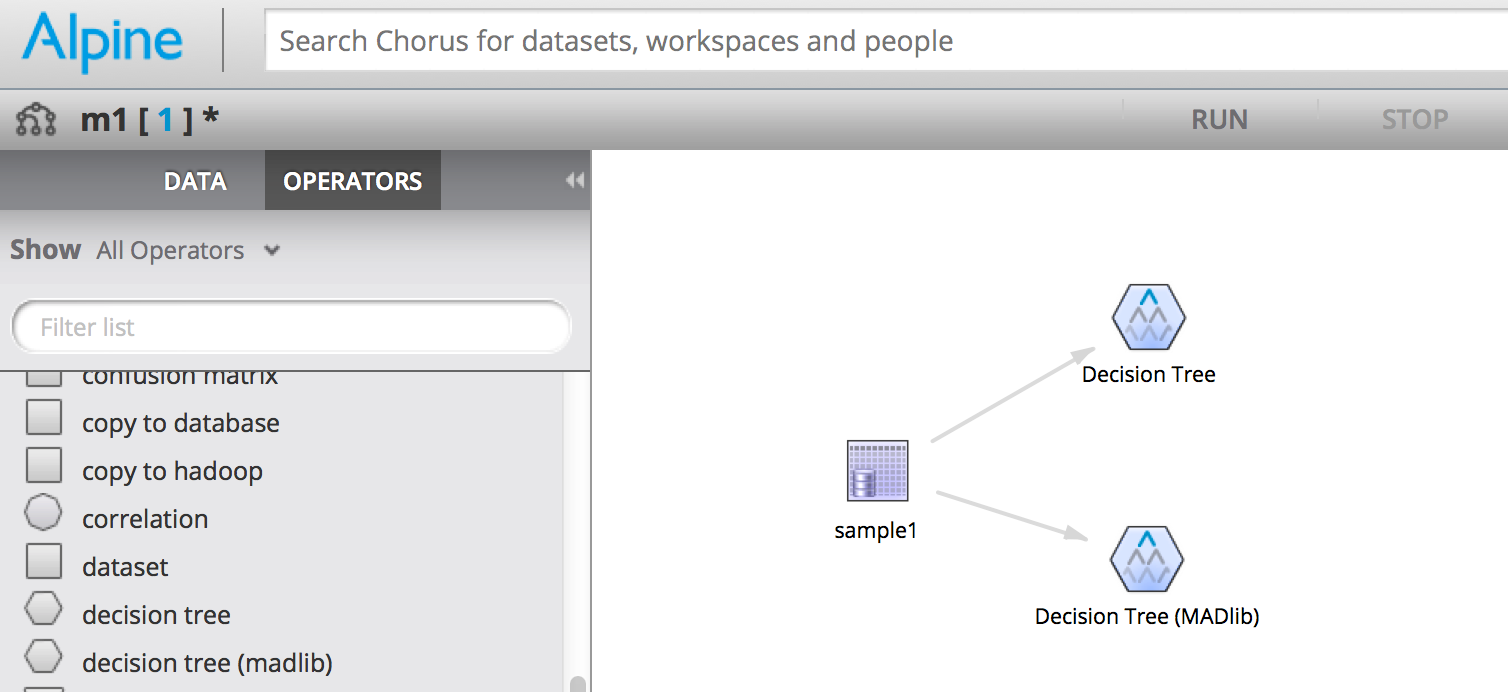
The Alpine Plugin Framework is available for any Alpine user to build their own custom operators. Users can create their own versions of common operators, or develop completely new functionality using the framework. Plugins can be kept private if they contain proprietary intellectual property, or they can be distributed to the open source community.
Building an Alpine Plugin
Alpine plugins are written in Java and are distributed as JAR files. New operators are immediately available in Alpine once the JAR file has been placed in the plugin directory on the Alpine server. Plugins simply implement the AnalyzerPlugin class which is included in the AlpineMinerSDK.jar distributed with Alpine.
Plugin developers override a set of methods that define how the operator should work. The first defines which database sources a given plugin will work with. In this example we specify that our operator will work only with Database sources, not Hadoop:
public DataSourceType getDataSourceType() {
return DataSourceType.DB;
}
Next we define the metadata associated with our plugin. This includes information such as the category, name, and icon that should be used for our operator in the GUI:
public PluginMetaData getPluginMetaData() {
return new PluginMetaData(
"Greenplum Data Operators",
"Dillon Woods",
1,
"Greenplum Insert Into",
"/com/alpine/plugin/madlib/resource/icon/join.png",
"Greenplum Insert Into"
);
}
We then declare the parameters needed by these operators. These are the parameters that users will configure through the GUI when they drag this operator onto the canvas. In this example we will have two parameters: a drop down box containing the schemas in the data source and a free form text input for the name of our table.
::java
public List<AlgorithmParameter> getParameters() {
List<AlgorithmParameter> parameterList = new ArrayList<AlgorithmParameter>();
parameterList.add( new SchemaNameParameter( "Schema Name", "" ) );
parameterList.add( new SingleValueParameter( "Table Name", null, "", ParameterType.STRING_TYPE, true ) );
return parameterList;
}
Finally we create the ‘run’ method that, as you might expect, is triggered when the user attempts to run this operator as part of a workflow. This example gets a connection to the database, builds a result set, and then returns the result to the user. In practice this would make calls to the data source, manipulate data, etc.
::java
public AnalyticModelGeneric run( AnalyticSource source, PluginRunningListener listener ) throws Exception {
PreparedStatement pstmt;
int retcode;
DataBaseAnalyticSource dbsource = (DataBaseAnalyticSource) source;
Connection conn = dbsource.getConnection();
List<String> columnNames = Arrays.asList( new String[] { "Step", "Result" } );
List<String> columnTypes = Arrays.asList( new String[] { GPSqlType.INSTANCE.getTextType(), GPSqlType.INSTANCE.getTextType() } );
List< List<String> > rows = new ArrayList< List<String> >();
rows.add( Arrays.asList( new String[] { "First Row", "First Value" } ) );
return result;
}
A few other methods are available for validation and localization, but this covers the core methods needed to develop a plugin.
Greenplum Data Operators
An example of three practical Alpine Plugins are the Alpine Greenplum Operators. This set of plugins provides three operators that are useful for manipulating data in a Greenplum database. The source code is available online and can be used as a template when building your own custom operators.
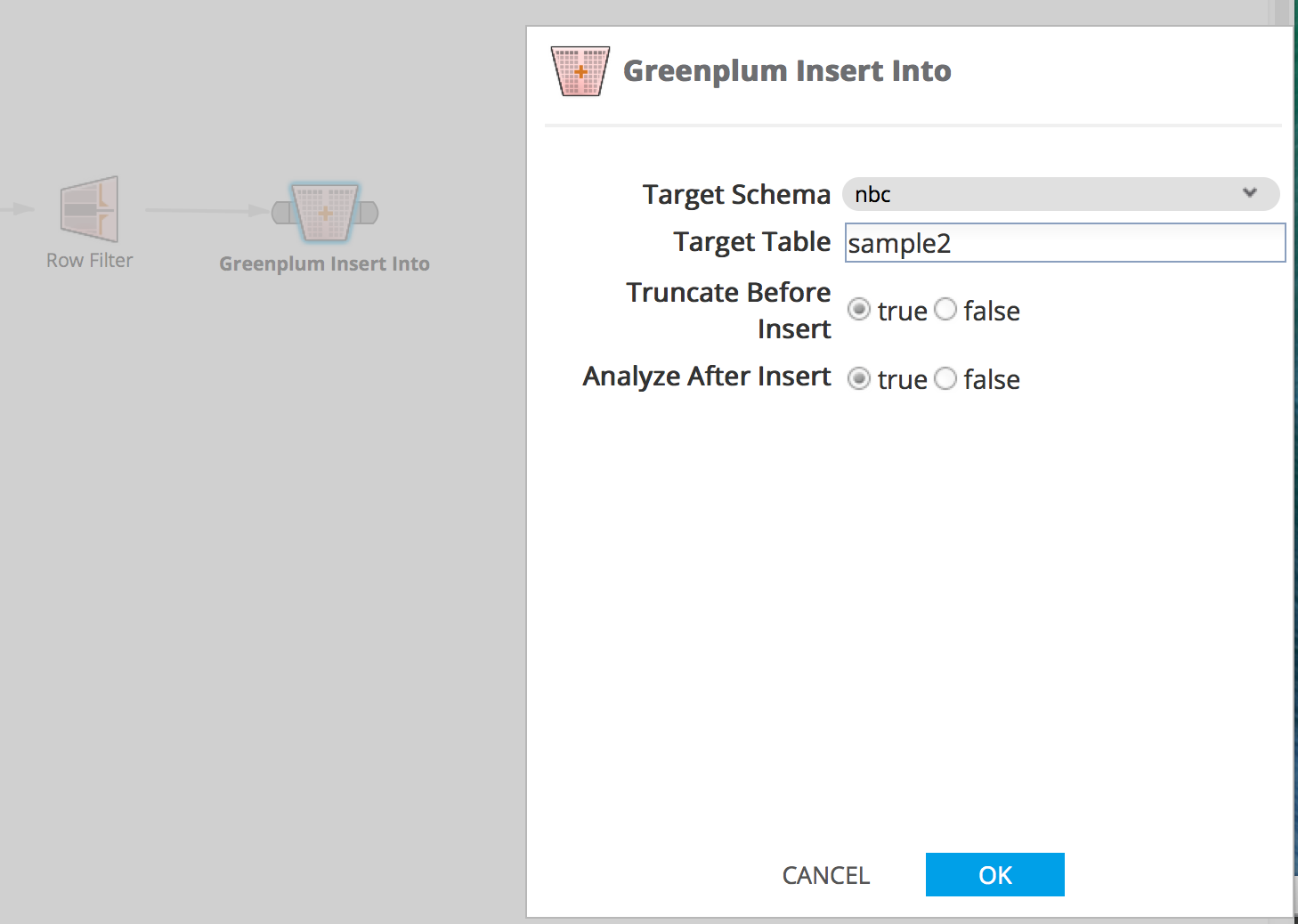
The first operator is used for simply inserting data into a Greenplum database. The source data can either come from a table, or it can be the result of a set of steps in the workflow. You can optionally choose to truncate the target table before inserting data or to analyze it after the insert completes. Simply connect your source data and specify your target table inside the operator parameters:
Greenplum Insert Into operator parameters:
The second operator allows you to update a Greenplum table based on a source data set. This utilizes the ‘UPDATE … FROM’ SQL syntax which updates each row in the target table for which a row with the same key exists in the source table. You specify the table key as a comma separated list of columns in the operator parameters and can optionally analyze the table after the update completes.
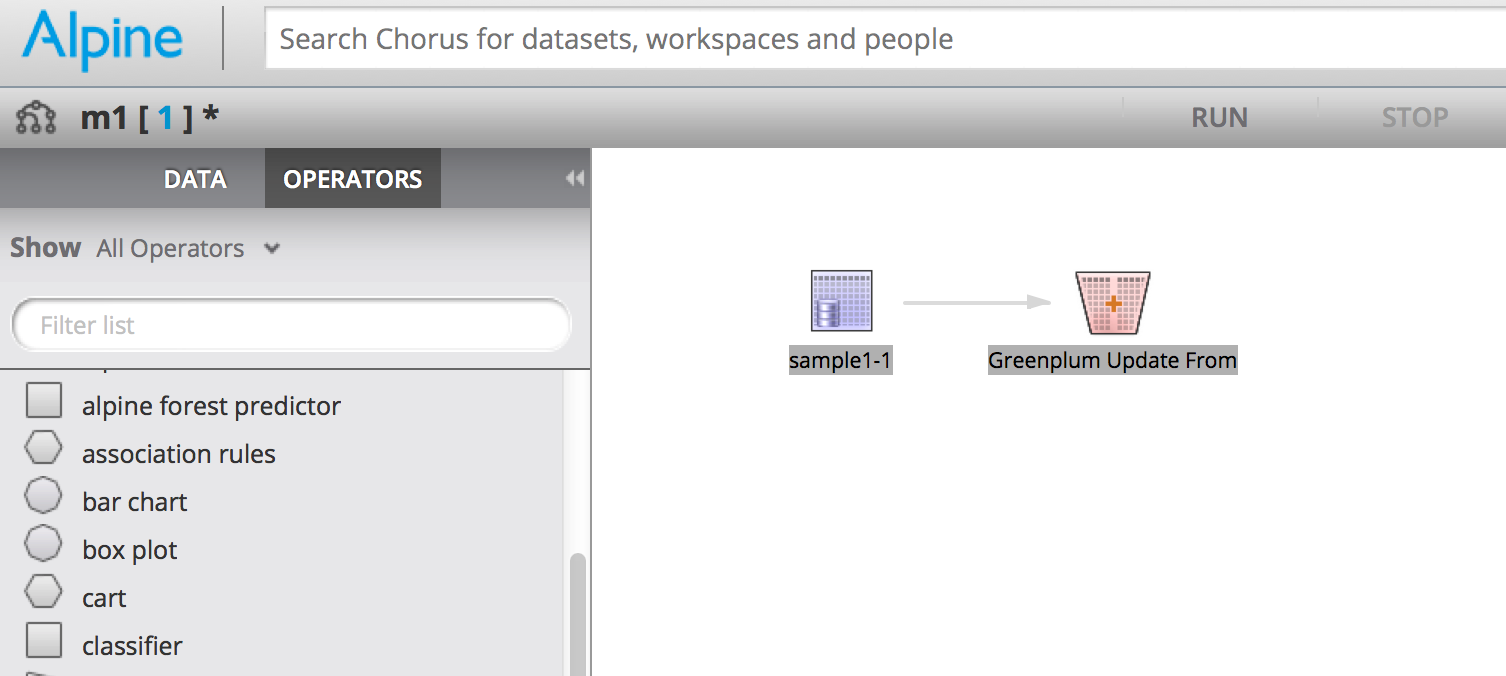
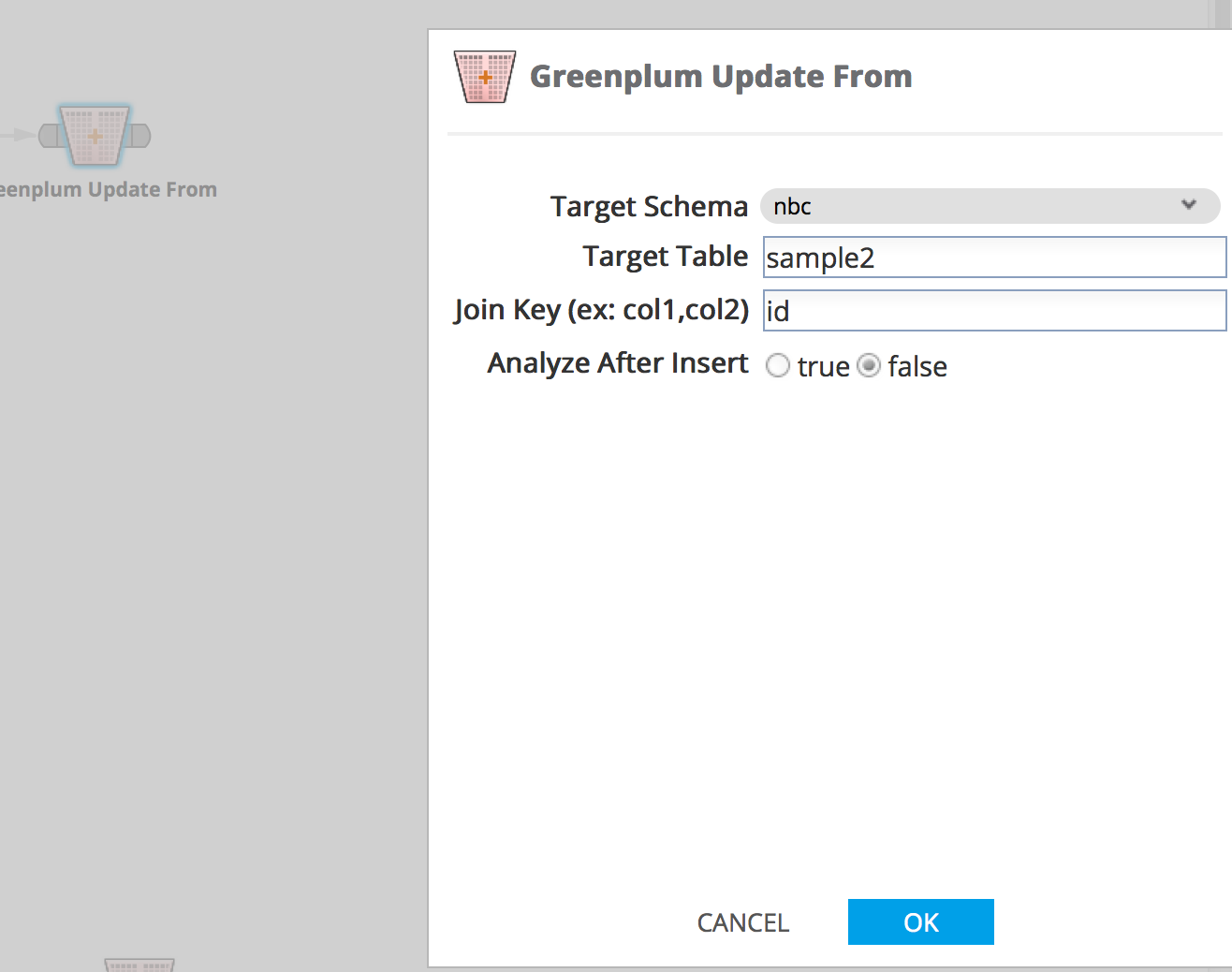
Greenplum Update From operator parameters:
The third operator is a Merge operator, which is a combination of the two above. That is, it first performs an update and then inserts any rows from the source that doesn’t yet exist in the target. It is also commonly known as an ‘Upsert’.
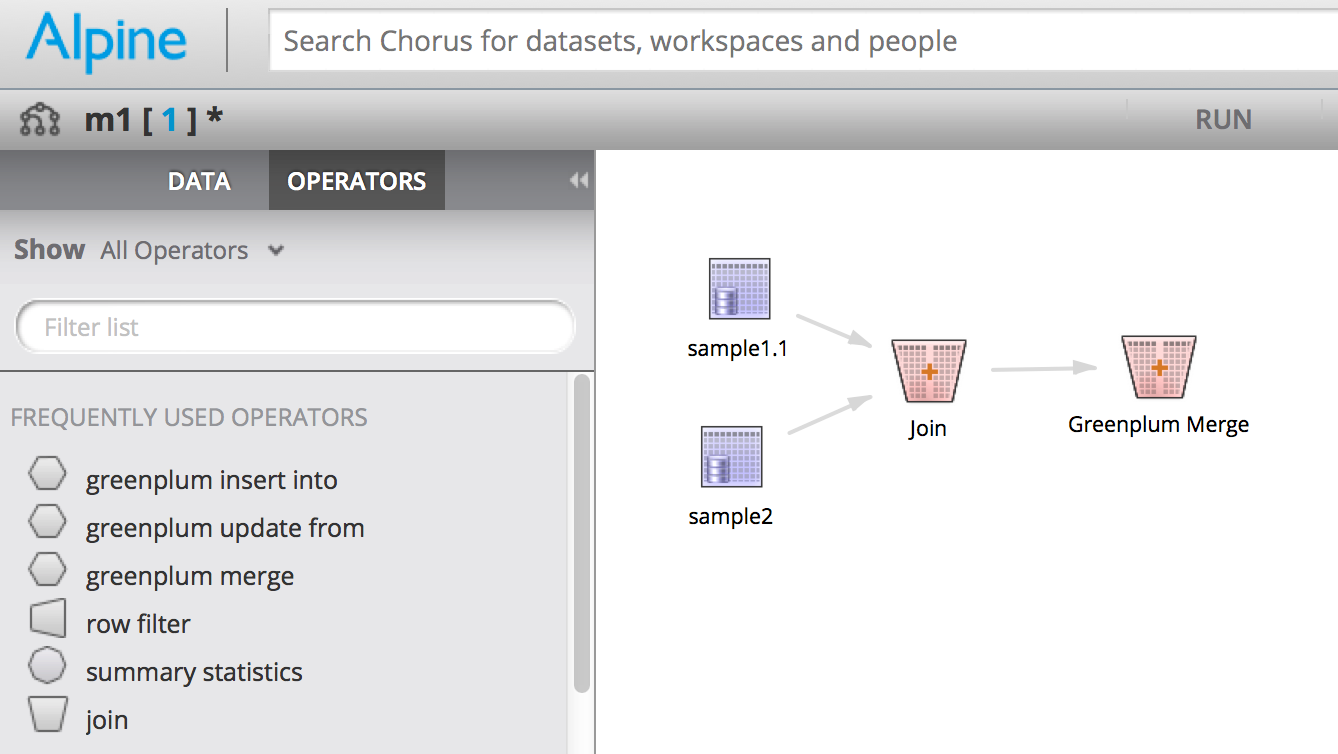
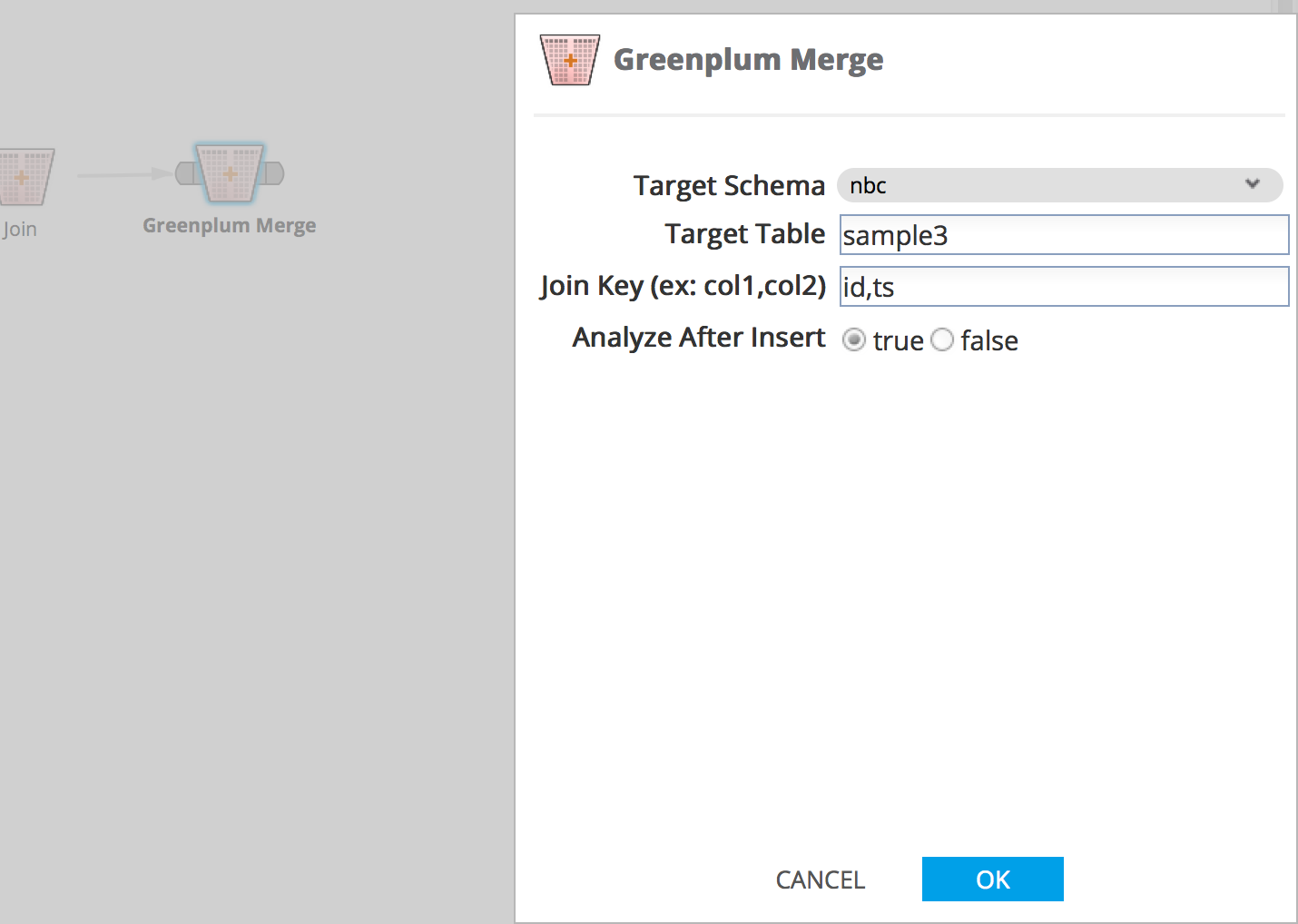
Greenplum Merge operator parameters:
Conclusion
Custom Operators are a useful way to extend the existing functionality of Alpine. They can be used as wrappers around libraries such as MADLib, or they can be used to implement brand new functionality for your data source of choice. Plugins can be used in Alpine visual workflows just like any other operator and can be controlled at run time via operator parameters. Users can create libraries of plugins for use within private organizations, or plugins can be shared via the open source community.
comments powered by Disqus